热线电话:0755-23712116
邮箱:contact@shuangyi-tech.com
地址:深圳市宝安区沙井街道后亭茅洲山工业园工业大厦全至科技创新园科创大厦2层2A


在计算机中有以下几个对象需要表示:
程序
整数
浮点数
字符串
逻辑值:0表示false,1表示true
在计算机中所有编码的基本元素都是通过0、1这两个基本符号来表示,n位可以表示2^n个不同的对象
逻辑型数据
True 真--1
False 假—0
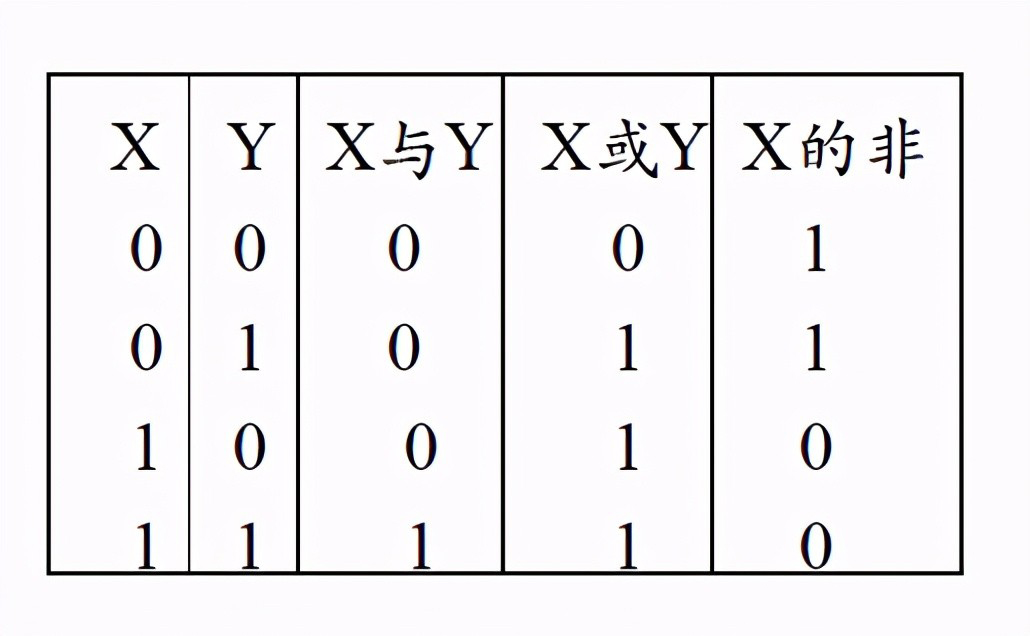
数据运算
与运算
或运算
非运算
异或运算
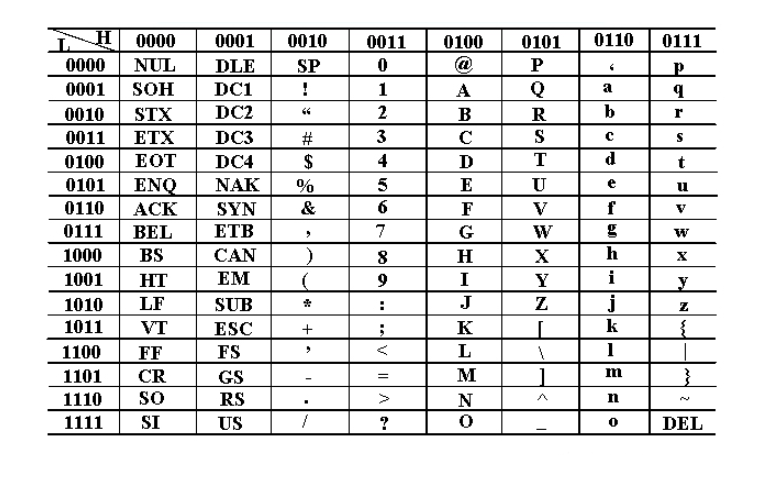
在很久之前,一群美国人研究出来了计算机,其中他们发现他们只需要8位二进制编码(一个字节)就可以表示世间万物(其实它们只使用了7位),2^7=128,它们用这128位,从0到127来存储数字和字母,这个编码就是我们熟悉的Ascii码
但是世界各国都用计算机,但是不使用中文,比如我们中国就不使用中文,所以这个时候中国研究出来了GB2312和GBK。当前其它国家也开发出来了符合本国国情的编码,那么这此时出现一个问题,就是自己国家用着很嗨,但是国与国之间交流的时候就含麻烦了。
所以为了解决这个问题,标记标准组织ISO着手解决这个问题,它们统一标准,包含所有国家的大多数的字符,这个标准编码就是Unicode,unicode开始制定的时候计算机的存储容量得到了极大的发展,所以它直接使用16个字符来表示一个字符,那么2^16=65536一共可以表示这么多的字符,它将整个编码空间划分为块,每块为16的倍数,然后按块进行分配。同时它保留了6400个码点供本地化使用。但是它仍然存在一个问题,就是这65536仍然是不够用啊,因为世界上有太多的字符需要表示了。
随着计算机的发展,现在已经是64位的了, 2^64据说可以表示地球上的每一粒沙子,所以问题很好解决,只需要通过64位来表示不就行了吗?
但是此时还是存在一个问题,这个问题就是在之前的时候ascii使用7个字节就可以表示出常用的数字和字母,那么现在使用64位来表示,岂不是太浪费空间了吗?不过没有什么可以难倒科学家的,科学家提出了UTF-8编码,这个是一个变长的字符编码,它可以提高存储空间的利用率。
首先它通过首字节来确定整个字符的长度,然后除了字符首字节外,均以“10”开始,这个编码太厉害了,能用7位表示的坚决不用31位表示,这样既可以表示大量的字符,又不会浪费太多的空间,所以它能为了互联网上占统治地位的字符集。
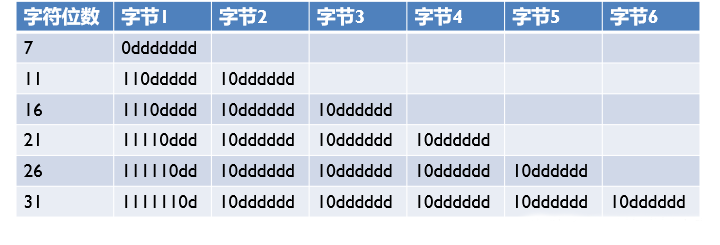
如图所示,我们可以看到字节1中前面的数字本标识字符的位数,当为0时表示7位,当110时表示11位,然后字节1之后的所有字节均通过10开头,这就是它的格式。
字符型就是常常通过utf-8来进行表示,那么现在我们来说说在计算机中是怎么存储数值型数据的,数值型分为两种一种是定点数,还有一种是浮点数。
其中定点数有三种情况,一种是整数、另一种是定点小数、还有一种是小数点位置固定。
浮点数有一种就是小数点位置浮动。
下面我们仅仅介绍整数。要想表示一个整数,首先需要确定数制,比如在现实生活中我们常常使用的数值是10进制,但是在计算机中使用的是二进制:
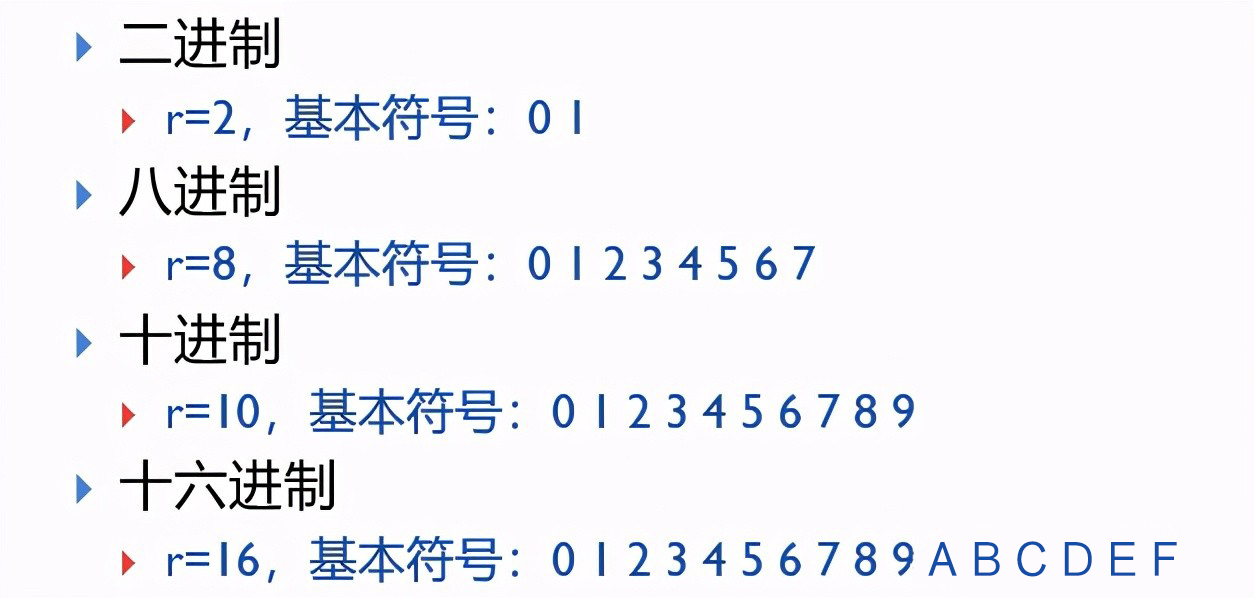
我们先来看一下二进制和十进制之间的转换:
二进制转成10进制
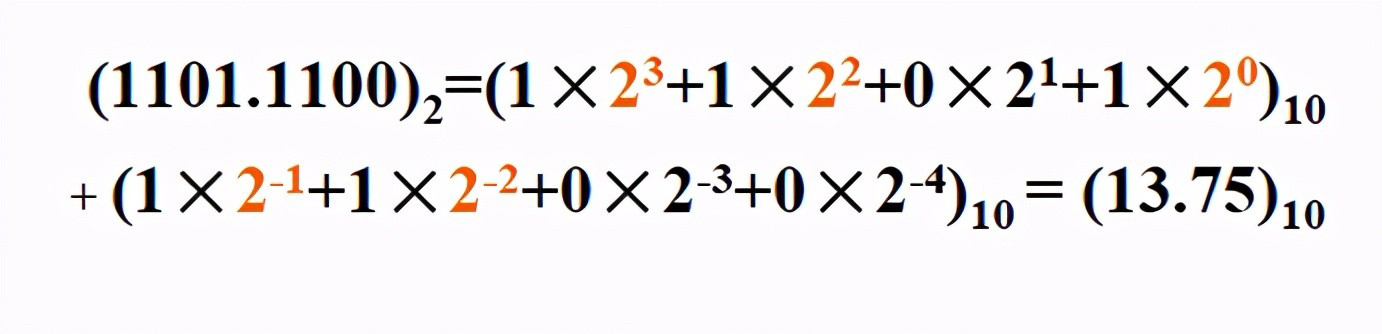
10进制转成2进制

把十进制数转换为二进制,对整数部分通过除2取余数来完成,对小数部分通过乘以2取整数来完成。
整数有正数和负数的区别,所以计算机中使用最高位来来表示正负数,其中0表示整数,1表示负数。其它位表示数据位,比如:
正数7,在计算机中用一个8位的二进制数来表示,是00000111,而负数-7,则用10000111表示
原码、反码、补码
正数的原码、反码、补码是一样的,而负数的反码等于源码除符号位取反,补码等于反码在最低为加1。
这里就会产生两个问题,第一个问题,为什么需要有反码和补码,它的意思是什么?第二为什么整数的反码和补码和源码是一样的。
首先在计算机中我们需要进行加减运算,但是会有下面的几种情况出现
我们来看看如果直接使用原码进行加减是否可以?
1+(-1)=[0000_00001]+[1000_0001]=[1000_0010]=-2
我们可以看到正数相加的时候毫无问题,但是一旦出现负数的情况就完蛋了,我们可以看到1-1可以看成是1+(-1)结果确不等于0,而是等于-2,这显然不符合我们的逻辑。
那么我们不使用源码来表示了我们使用反码来计算,
-1的原码是[1000_0001]、反码[1111_1110]
2的源码是[0000_0010]、反码[0000_0010]
-1+2=[1111_1110]+[0000_0010]=[0000_0000]=0
我们发现这也不符合逻辑,-1+2应该等于0
那么下面我们再来使用补码来试一下:
-1的原码是[1000_0001]、反码[1111_1110]、补码[1111_1111]
2的源码是[0000_0010]、反码[0000_0010]、补码[0000_0010]
-1+2=[1111_1111]+[0000_0010]=[0000_0001]=1
我们发现这个是符号我们的逻辑的,所以回答第二个问题,为什么要有补码呢?这就是因为只有补码可以保证我们的加减运算是正确的,但是为什么会出现这种情况呢?

我们可以发现在负原码中每增加一个二进制单位对应的是递减的(1000_0001和1000——0000相比)按照道理来说1000_0001应该比1000_0000大,但是事实确相反,而正每增加一个二进制单位对应的真数是递增的,这个符合我们的需要,为了解决负数的这个问题,我们可以取反码
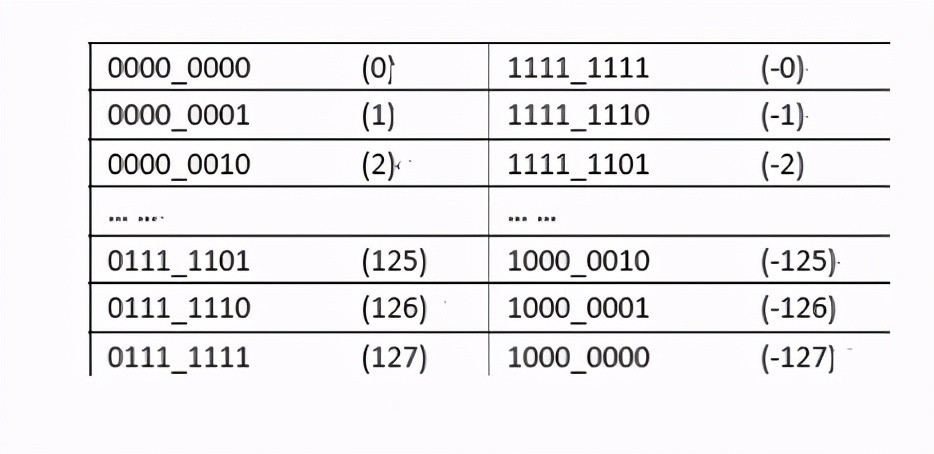
我们可以发现反码满足了负原码中每增加一个二进制单位对应的是递增的(1111_1110和1111_1111相比,1111_1111比1111_11110大),解决第一个问题之后,还有第二个问题,这个问题就是0的问题,因为没有正0和负零的说法,但是上面确有正零和负零区别,这就导致了重复的问题,这个时候我们发现当给负原码加1,那么0就统一了,如下所示:
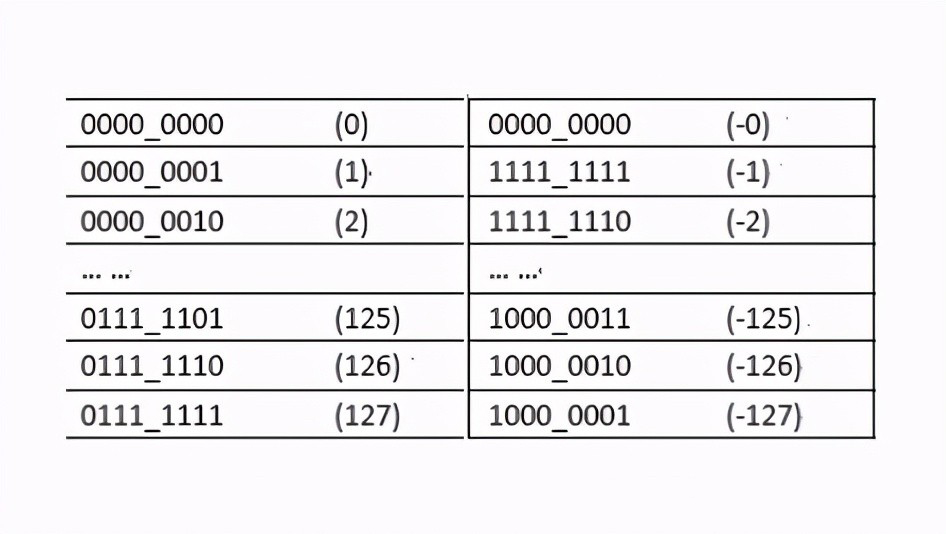
那么问题就解决了,那么还需要注意的是1000_0000这个反码表示-128,所以补码的表示范围是[-128~127] ,这样一来256个二进制正好表示256个整数
码距是指任意两个合法码之间至少有几个二进制位不相同。
仅有一位不同的编码是无纠错能力的,例如用4位二进制表示16种状态,则16种编码都用到了,此时码距为1。任意一个编码状态的四位码中的一位或者几位出错,都会变成另外一个合法码,那么这种编码是没有检错能力的。
若用4个二进制位表示8种合法的状态,那么就可以只使用其中的8个编码来表示,另外8个为非法编码,那么合法的码距为2。因为此时任何一位出错后都会成为非法码,这样有检测一位出错的能力。
合理增大码距,那么就能提高错误的能力,但是会使用更多的二进制,增加了电子路线的复杂性和数据存储、数据传送的数量。
常用的检错纠错码有以下几种:

先对原始数据使用校验码进行编码(加进特征),然后传输,传输完成之后进行译码,然后判断收到的码字是否有问题
下面我们讲解一下奇偶校验
原理是在k位数据码之外增加1位校验位,使得K+1位码字中取值1的位数总保持为偶数(偶效验)或奇数(寄校验),举一个例子:

对待传输数据10110110约定采用其校验时,发送方所需要发送的校验码为010110110,对于接收方来说,如果接收到的数据中’1’的个数不为奇数时,就会认为数据出错。但是它并不知道哪里出错了,也就是它没有纠错的能力。
热线电话:0755-23712116
邮箱:contact@shuangyi-tech.com
地址:深圳市宝安区沙井街道后亭茅洲山工业园工业大厦全至科技创新园科创大厦2层2A
